Listcrawer – Listcrawler, a powerful tool for data extraction, opens up exciting possibilities across various domains. This comprehensive guide delves into the intricacies of listcrawlers, exploring their functionality, ethical considerations, technical aspects, and diverse applications. From understanding the legal and ethical implications of data scraping to mastering advanced techniques like handling dynamic websites and optimizing performance, we’ll equip you with the knowledge to harness the power of listcrawlers responsibly and effectively.
We will cover a range of topics, including different data extraction methods, programming languages used in listcrawler development, strategies for overcoming anti-scraping measures, and efficient data storage and management techniques. Whether you’re an experienced developer or just beginning to explore the world of data extraction, this guide offers valuable insights and practical guidance.
Listcrawlers: Definition, Functionality, and Ethical Considerations
Listcrawlers are automated programs designed to extract structured data from websites. They play a crucial role in various applications, from market research to e-commerce. However, their use necessitates careful consideration of ethical and legal implications.
Core Functionality of a Listcrawler
A listcrawler’s core functionality involves systematically navigating a website, identifying relevant data points, and extracting them in a structured format. This typically involves identifying target URLs, fetching the HTML content, parsing the HTML to locate specific data elements (like product names, prices, or contact information), and storing the extracted data in a database or file.
Types of Data Extracted by Listcrawlers
Listcrawlers can extract a wide variety of data, depending on the target website and the crawler’s design. Common examples include product information (name, price, description, reviews), contact details (names, email addresses, phone numbers), news articles, research papers, and social media posts.
Examples of Websites for Listcrawler Usage
E-commerce platforms (Amazon, eBay), job boards (Indeed, LinkedIn), real estate websites (Zillow, Realtor.com), and news aggregators are frequent targets for listcrawlers. Academic databases are also commonly scraped for research purposes.
Comparison of Listcrawler Techniques
Different techniques exist for building listcrawlers, each with its advantages and disadvantages.
| Technique | Data Source | Complexity | Legal/Ethical Concerns |
|---|---|---|---|
| Web Scraping | Website HTML | Moderate to High | High (Terms of Service violations possible) |
| API Usage | Website API | Low to Moderate | Low (if API usage is permitted) |
| Database Queries (if applicable) | Website Database (if accessible) | Low to Moderate | Very High (requires explicit authorization) |
| Screen Scraping | Rendered webpage (screenshot) | High | High (often violates Terms of Service) |
Ethical and Legal Considerations of Listcrawlers: Listcrawer
The use of listcrawlers raises significant ethical and legal concerns, particularly regarding data privacy and compliance with website terms of service.
Legal Implications of Using Listcrawlers
Using listcrawlers to collect data without proper authorization can lead to legal repercussions. This includes potential violations of copyright laws, terms of service agreements, and data privacy regulations (like GDPR and CCPA).
Ethical Considerations Regarding Data Privacy and Scraping
Ethical considerations center around respecting user privacy and avoiding the unauthorized collection of sensitive personal information. Transparency and obtaining consent, where appropriate, are crucial ethical principles.
Potential Risks Associated with Unauthorized Data Collection
Unauthorized data collection can damage a website’s reputation, lead to legal action, and result in the blocking of the crawler’s IP address. It can also compromise user privacy and security.
Best Practices for Responsible Listcrawler Development and Usage
Responsible listcrawler development involves respecting robots.txt, adhering to website terms of service, and avoiding the collection of personally identifiable information without consent. Implementing rate limiting to avoid overwhelming the target website’s server is also crucial.
Technical Aspects of Listcrawler Development
Building a listcrawler involves a combination of algorithm design, programming skills, and an understanding of web technologies.
Basic Listcrawler Algorithm (Pseudocode)
A simplified algorithm might look like this:
BEGIN 1. Define target URLs. 2. Fetch HTML content from each URL. 3. Parse HTML to extract relevant data. 4. Clean and transform extracted data. 5. Store data in a database or file. END
Role of Programming Languages in Listcrawler Development
Python, with its extensive libraries like Beautiful Soup and Scrapy, is a popular choice for listcrawler development due to its ease of use and powerful capabilities. Other languages like Java, Node.js, and Ruby are also used.
Common Challenges During Listcrawler Development
Challenges include handling dynamic websites (those that heavily rely on JavaScript), dealing with anti-scraping measures, managing large datasets, and ensuring data accuracy and consistency.
Step-by-Step Guide for Building a Simple Listcrawler (Python)
A simple Python listcrawler would involve installing necessary libraries (requests, Beautiful Soup), defining target URLs, fetching the HTML content using the `requests` library, parsing the HTML using Beautiful Soup to extract the desired data, and finally storing the data in a structured format (e.g., CSV or JSON).
Do not overlook explore the latest data about bedpage.
Applications and Use Cases of Listcrawlers
Listcrawlers find applications across numerous industries and domains, providing valuable insights and automating data collection tasks.
Listcrawlers in E-commerce
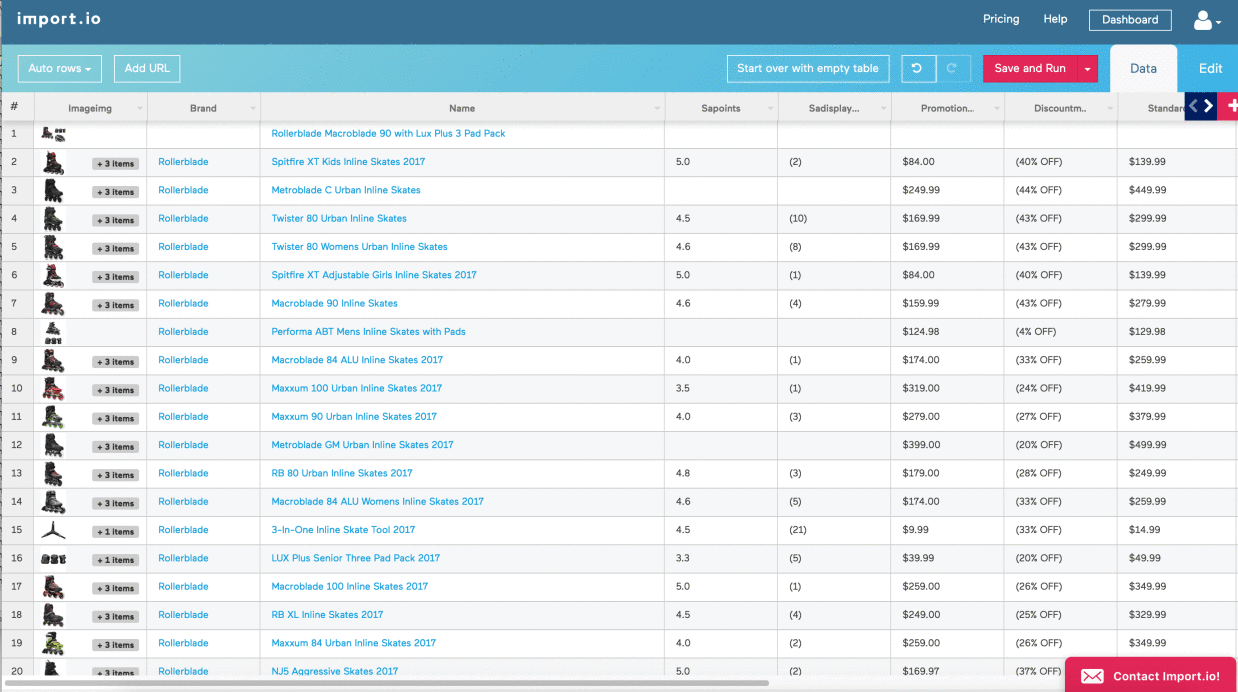
In e-commerce, listcrawlers are used for price comparison, competitor analysis, product monitoring, and inventory management. They automate the process of collecting data from multiple online stores, enabling businesses to make informed decisions.
Listcrawlers in Market Research
Market researchers utilize listcrawlers to gather data on consumer sentiment, product reviews, and market trends. This data helps in understanding customer preferences and shaping marketing strategies.
Listcrawlers in Academic Research
Researchers use listcrawlers to collect data from various sources for research purposes, such as gathering scientific publications, news articles related to a specific topic, or analyzing social media trends related to a research subject.
Applications of Listcrawlers Across Different Industries
- Finance: Monitoring stock prices, news, and financial reports.
- Real Estate: Gathering property listings and market data.
- Social Media: Analyzing social media trends and sentiment.
- Recruitment: Collecting job postings and candidate information.
- News Aggregation: Gathering news articles from multiple sources.
Advanced Listcrawler Techniques
Advanced techniques are necessary to overcome challenges posed by sophisticated websites and anti-scraping measures.
Rotating Proxies and Their Importance in Listcrawling
Rotating proxies help mask the crawler’s IP address, preventing website blocks and improving the crawler’s ability to access data without being detected. This is particularly important when dealing with websites that employ IP-based restrictions.
Handling Dynamic Websites and JavaScript Rendering
Dynamic websites rely heavily on JavaScript to load content. Techniques like using headless browsers (like Selenium or Puppeteer) or employing JavaScript rendering services can be used to extract data from these websites.
Overcoming Anti-Scraping Measures, Listcrawer
Websites employ various anti-scraping measures, such as CAPTCHAs, rate limiting, and IP blocking. Techniques to overcome these include using CAPTCHA solving services, implementing sophisticated rate limiting strategies, and employing rotating proxies.
Data Parsing and Cleaning Techniques
Efficient data parsing involves using tools like Beautiful Soup or regular expressions to extract relevant information from HTML. Data cleaning involves handling missing values, removing duplicates, and transforming data into a consistent format.
Performance Optimization and Scalability of Listcrawlers
Optimizing a listcrawler’s performance and scalability is crucial for handling large datasets and ensuring efficient data collection.
Strategies for Optimizing Listcrawler Speed and Efficiency
Optimizations include using asynchronous requests, minimizing HTTP requests, caching frequently accessed data, and employing efficient data parsing techniques.
Techniques for Handling Large Datasets Efficiently
Handling large datasets efficiently involves using databases optimized for large-scale data storage and retrieval (e.g., NoSQL databases), data compression techniques, and parallel processing.
System Architecture for a Scalable Listcrawler
A scalable architecture might involve a distributed system with multiple crawlers working in parallel, a message queue for task management, and a robust data storage system.
Workflow of a Highly Efficient Listcrawler (Flowchart Description)
A highly efficient listcrawler workflow would involve a queue of URLs, parallel processing of these URLs by multiple crawler instances, data extraction and cleaning, data storage in a database, and potentially data analysis and reporting. The system would incorporate error handling and retry mechanisms to ensure robustness.
Data Storage and Management
Effective data storage and management are critical for organizing and utilizing the data collected by a listcrawler.
Methods for Storing Data Extracted by a Listcrawler
Data can be stored in various formats, including relational databases (like MySQL or PostgreSQL), NoSQL databases (like MongoDB or Cassandra), CSV files, JSON files, or cloud-based storage solutions.
Benefits and Drawbacks of Various Database Systems

Relational databases offer structured data storage and efficient querying, but can be less scalable for massive datasets. NoSQL databases offer better scalability but may require more complex data modeling.
Data Cleaning and Transformation Techniques
Data cleaning involves handling missing values, correcting inconsistencies, and removing duplicates. Data transformation involves converting data into a suitable format for analysis and reporting.
Organizing and Managing Large Datasets from Listcrawlers
Managing large datasets requires efficient indexing, data partitioning, and potentially the use of specialized data warehousing or big data processing tools.
Ultimately, mastering the art of listcrawling requires a delicate balance between technical expertise and ethical awareness. By understanding the legal implications, respecting data privacy, and employing responsible development practices, we can leverage the power of listcrawlers to extract valuable insights while upholding the highest standards of integrity. This guide serves as a starting point for your journey into the world of listcrawlers, empowering you to explore its vast potential while navigating its inherent complexities responsibly.
General Inquiries
What are the limitations of listcrawlers?
Listcrawlers can be limited by website structure, anti-scraping measures, and the rate at which data can be processed. They may also struggle with dynamic content loaded via JavaScript.
How can I avoid legal issues when using a listcrawler?
Always respect robots.txt, adhere to a website’s terms of service, and avoid collecting personally identifiable information without consent. Consider using APIs where available.
What are some alternatives to listcrawlers?
Alternatives include using publicly available APIs, purchasing data from reputable providers, or employing manual data entry (for smaller datasets).
Can I use a listcrawler to scrape data from social media platforms?
Scraping social media platforms is often restricted by their terms of service and may violate their policies. Using their official APIs is generally the preferred and legally sound approach.