Listcrawller, at its core, is a powerful tool for systematically extracting data from websites. This exploration delves into the intricacies of listcrawllers, examining their functionality, ethical considerations, and diverse applications. We will navigate the technical aspects of data extraction, comparing various techniques and addressing the challenges posed by dynamic websites and anti-scraping measures. Prepare to uncover the potential and limitations of this fascinating technology.
This comprehensive guide provides a detailed overview of listcrawllers, from their fundamental architecture and data extraction methods to advanced optimization strategies and ethical considerations. We will cover a wide range of topics, including legal compliance, best practices, and practical examples to illustrate the process of building and deploying a functional listcrawller.
Listcrawlers: A Comprehensive Overview
Listcrawlers are automated programs designed to systematically extract data from websites, typically focusing on lists or structured data. This overview explores their functionality, data extraction techniques, ethical considerations, applications, and advanced optimization strategies.
Definition and Functionality of a Listcrawler, Listcrawller
A listcrawler is a type of web crawler specifically designed to extract lists of data from websites. Its core functionality involves navigating website pages, identifying target data within lists or structured formats, and extracting this data for storage and further processing. This differs from general web crawlers which might focus on indexing entire websites for search engines. The architecture typically includes components such as a URL scheduler, a web page fetcher, an HTML parser, a data extractor, and a data storage mechanism.
Listcrawler Architecture Components
A typical listcrawler architecture comprises several key components working in concert. These include a URL scheduler that manages the queue of URLs to visit, a web page fetcher that retrieves the HTML content of each URL, an HTML parser that analyzes the HTML structure to locate target data, a data extractor that extracts the specific data elements from the parsed HTML, and a data storage component (database, file system, etc.) that stores the extracted information.
Do not overlook the opportunity to discover more about the subject of bloxburg house layout.
Types of Listcrawlers
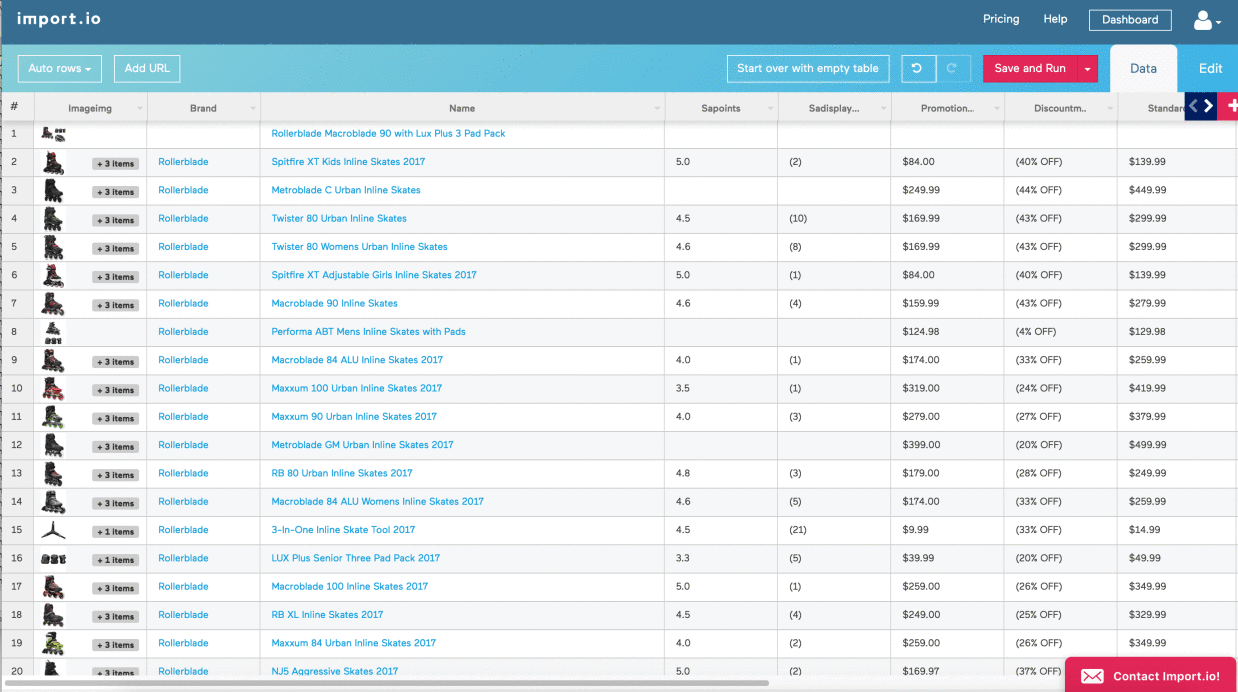
Listcrawlers can be categorized based on their target data. For example, a product list crawler might extract product details from e-commerce sites, while a news crawler could gather headlines and summaries from news websites. Another example is a job listing crawler, designed to collect job postings from job boards.
Listcrawler Operational Flowchart
A basic listcrawler follows a cyclical process. It begins with an initial URL, fetches the page, extracts data, stores it, then identifies and adds new URLs to the queue from links on the fetched page. This continues until the queue is empty or a predetermined stopping criterion is met. A visual representation would show a loop including: Fetch URL -> Parse HTML -> Extract Data -> Store Data -> Add new URLs to Queue.
Data Extraction Techniques Employed by Listcrawllers
Efficient data extraction is crucial for listcrawlers. Various techniques exist, each with its own strengths and weaknesses. The choice depends on the website’s structure and the complexity of the data.
Data Extraction Methods
Common methods include using regular expressions to identify patterns in the HTML, employing CSS selectors to target specific elements based on their style attributes, and utilizing XPath expressions to navigate the XML-like structure of HTML documents. Each method has varying levels of complexity and robustness.
Efficiency Comparison of Data Extraction Techniques
Regular expressions offer flexibility but can be less efficient for complex HTML structures. CSS selectors provide a more targeted approach, while XPath offers a powerful mechanism for navigating complex document structures. The optimal choice depends on the specific website and data format.
Challenges of Extracting Data from Dynamic Websites
Dynamic websites, which use JavaScript to load content, present significant challenges. Simple HTML parsing may not capture the data loaded dynamically. Techniques like using headless browsers (simulating a browser environment) or employing JavaScript rendering libraries are often necessary to handle such scenarios.
Handling Pagination in Listcrawlers
Pagination, where data is spread across multiple pages, requires specific handling. Listcrawlers need to identify pagination links and recursively follow them to extract data from all pages. This often involves detecting patterns in URLs or analyzing HTML for “next page” links.
Web Scraping Libraries Comparison
Several libraries facilitate web scraping. The table below compares some popular options.
| Library | Strengths | Weaknesses | Language |
|---|---|---|---|
| Beautiful Soup | Easy to learn, versatile parsing | Can be slower for large-scale scraping | Python |
| Scrapy | Fast, scalable, built-in features | Steeper learning curve | Python |
| Cheerio | Fast, jQuery-like syntax | Limited features compared to Scrapy | JavaScript (Node.js) |
| Puppeteer | Handles JavaScript rendering well | Resource-intensive | JavaScript (Node.js) |
Ethical and Legal Considerations of Listcrawler Usage: Listcrawller
Responsible use of listcrawlers is paramount. Ignoring ethical and legal guidelines can lead to serious consequences.
Ethical Implications of Listcrawler Use
Ethical considerations include respecting website owners’ wishes, avoiding overloading servers, and ensuring data privacy. Overloading a website with requests can lead to denial-of-service issues, negatively impacting legitimate users.
Legal Issues Associated with Web Scraping
Legal issues include copyright infringement, violation of terms of service, and potential breaches of privacy laws. Websites often have terms of service explicitly prohibiting scraping. Furthermore, scraping personal data without consent can be illegal.
Best Practices for Responsible Listcrawler Development
Best practices include respecting robots.txt directives, adhering to website terms of service, implementing polite scraping techniques (e.g., using delays between requests), and ensuring data privacy.
Respecting robots.txt and Website Terms of Service
Robots.txt files specify which parts of a website should not be crawled. Adhering to these directives is crucial. Similarly, always review and comply with a website’s terms of service before scraping.
Potential Legal Ramifications of Violating Website Terms
- Cease and desist letters
- Lawsuits for copyright infringement
- Legal action for breach of contract
- Financial penalties
Applications and Use Cases of Listcrawllers
Listcrawlers find applications across various industries, enabling efficient data collection for diverse purposes.
Industries and Applications Benefiting from Listcrawlers
E-commerce businesses use listcrawlers for price comparison, competitor analysis, and product monitoring. Market research firms leverage them for gathering data on consumer trends and preferences. News aggregators use listcrawlers to compile news headlines from various sources.
Successful Listcrawler Deployments
Many companies use listcrawlers for tasks such as monitoring social media sentiment, tracking brand mentions, and gathering customer reviews. While specific case studies often remain confidential for competitive reasons, the general impact is widespread across many sectors.
Potential E-commerce Applications for Listcrawlers

- Product price monitoring
- Competitor analysis
- Inventory tracking
- Customer review aggregation
Listcrawlers for Market Research
Listcrawlers can be used to gather data on consumer preferences, product reviews, and competitor offerings. This data can then be analyzed to inform marketing strategies, product development, and business decisions. For example, a market research firm might use a listcrawler to collect data on customer reviews of a particular product from various e-commerce sites.
Advanced Techniques and Optimization Strategies
Optimizing listcrawlers for speed, efficiency, and error handling is essential for handling large-scale data extraction.
Improving Listcrawler Speed and Efficiency
Techniques include using asynchronous requests, employing caching mechanisms, and optimizing data parsing algorithms. Asynchronous requests allow the crawler to make multiple requests concurrently, significantly reducing overall crawling time.
Handling Errors and Exceptions

Robust error handling is critical. This involves implementing mechanisms to catch and handle network errors, timeouts, and parsing errors. Retry mechanisms and logging capabilities are essential for diagnosing and resolving issues.
Managing Large Datasets
Efficient data management is crucial for large datasets. This might involve using databases (like MongoDB or PostgreSQL) for structured storage, employing distributed processing techniques, and implementing data compression strategies.
Deploying a Listcrawler to a Cloud Environment
Deploying to a cloud environment (AWS, Google Cloud, Azure) offers scalability and reliability. This typically involves containerization (Docker) and orchestration (Kubernetes) to manage the listcrawler’s resources efficiently.
Avoiding Detection by Anti-Scraping Measures
Websites often implement anti-scraping measures. Techniques to mitigate detection include rotating IP addresses, using user-agent spoofing, and implementing delays between requests to mimic human behavior.
Illustrative Example: A Simple Listcrawler Implementation
Consider a simple listcrawler designed to extract product names and prices from an e-commerce website. The crawler would first fetch the product listing page, then parse the HTML to identify elements containing product names and prices using CSS selectors or XPath. The extracted data would be stored in a structured format (e.g., a list of dictionaries or a CSV file).
Data Structures
The crawler might use a dictionary to represent each product, with keys for “name” and “price.” A list would then contain these dictionaries, representing all extracted products.
Storing and Managing Extracted Data
The initial URL is added to the queue.
The crawler fetches the page and parses the HTML.
Data is extracted using CSS selectors or XPath and stored in a list of dictionaries.
The list of dictionaries is written to a CSV file or stored in a database.
In conclusion, listcrawllers represent a potent technology with far-reaching applications across numerous industries. While offering immense potential for data-driven insights and automation, responsible development and deployment are paramount. By understanding the ethical and legal implications, along with best practices for efficient data extraction, we can harness the power of listcrawllers while upholding responsible data collection and usage.
Question Bank
What are the limitations of using a listcrawller?
Listcrawllers can be limited by website structure changes, anti-scraping measures implemented by websites, and the potential for legal repercussions if terms of service are violated. Speed and efficiency can also be affected by factors such as server response times and data volume.
How can I avoid detection by anti-scraping measures?
Techniques to avoid detection include rotating IP addresses, using delays between requests, respecting robots.txt, and mimicking human browsing behavior. However, sophisticated anti-scraping measures can be challenging to circumvent.
What are the best practices for responsible listcrawller development?
Always respect robots.txt, adhere to website terms of service, implement politeness mechanisms (e.g., delays between requests), and handle errors gracefully. Prioritize ethical considerations and data privacy.