
Listcrowler – ListCrawler, a powerful tool for data extraction, opens up a world of possibilities for businesses and researchers alike. This comprehensive guide explores the functionalities, techniques, and ethical considerations surrounding ListCrawler, providing a clear understanding of its capabilities and limitations. We’ll delve into various data extraction methods, data cleaning processes, and legal implications, equipping you with the knowledge to utilize ListCrawler effectively and responsibly.
From understanding its core purpose and target data sources to mastering advanced techniques like handling CAPTCHAs and optimizing performance, this guide covers all aspects of ListCrawler usage. We will also examine the ethical and legal considerations associated with data scraping, ensuring you navigate this powerful tool with confidence and adherence to best practices.
Understanding ListCrawler Functionality
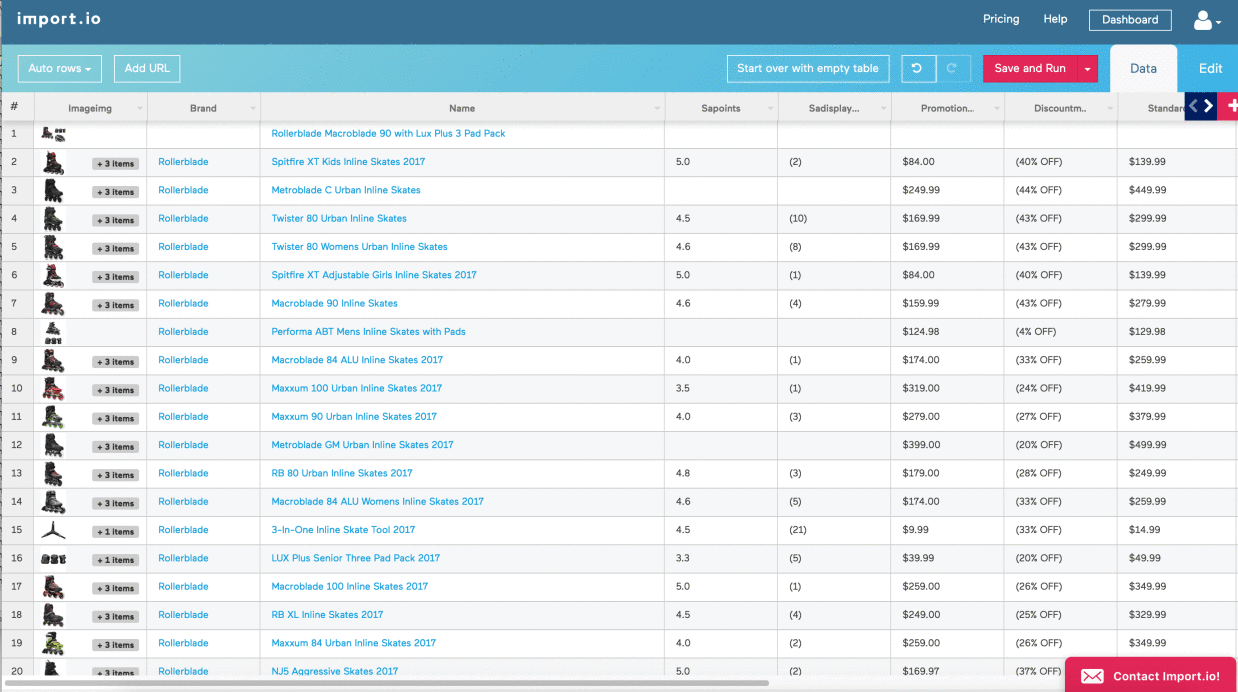
ListCrawlers are specialized web data extraction tools designed to efficiently gather information from online lists and directories. They differ from general-purpose web scraping tools by focusing on structured data presented in list formats, enabling more targeted and efficient data collection.
Core Purpose of a ListCrawler
The primary purpose of a ListCrawler is to systematically extract data from online lists, directories, and other structured data sources. This involves identifying, navigating, and extracting relevant information from each item within a list, often automating a process that would be extremely time-consuming if done manually.
Typical Data Sources for ListCrawlers
ListCrawlers target various online data sources, including e-commerce product catalogs, real estate listings, job boards, news aggregators, and social media profiles. These sources often present data in tabular or list-like formats, making them ideal targets for ListCrawler applications.
Data Extraction Methods Used by ListCrawlers
ListCrawlers employ several techniques to extract data. These include parsing HTML and XML structures to identify list items, using regular expressions to locate specific data fields, and leveraging APIs (where available) to access data programmatically. Advanced ListCrawlers may employ machine learning techniques to improve accuracy and handle variations in data formats.
Comparison of ListCrawlers and Web Scraping Tools
While both ListCrawlers and web scraping tools extract data from websites, they differ in their focus and capabilities. ListCrawlers excel at extracting data from structured lists and directories, offering targeted and efficient data collection. General-purpose web scraping tools are more versatile but may require more complex configuration and processing for structured data extraction.
ListCrawler Applications Across Industries, Listcrowler
| Industry | Application | Data Source | Benefits |
|---|---|---|---|
| E-commerce | Price comparison, product monitoring | Online retailer product catalogs | Competitive pricing analysis, inventory tracking |
| Real Estate | Property listings aggregation, market analysis | Real estate portals | Improved property search, market trend identification |
| Recruitment | Job postings aggregation, candidate screening | Job boards | Faster recruitment process, efficient candidate identification |
| Financial Services | Market data aggregation, risk assessment | Financial news websites, stock exchanges | Improved investment decisions, enhanced risk management |
ListCrawler Data Extraction Techniques
Efficient and effective data extraction using ListCrawlers requires understanding common challenges and employing appropriate techniques. This section details methods for handling dynamic content, optimizing performance, and managing pagination.
Challenges in ListCrawler Data Extraction
Common challenges include handling dynamic web content (data loaded via JavaScript), dealing with pagination (multiple pages of results), managing inconsistent data formats, and avoiding anti-scraping measures implemented by websites. Robust ListCrawlers must address these challenges effectively.
Handling Dynamic Web Content
Techniques for handling dynamic content include using headless browsers (like Selenium or Puppeteer) to render JavaScript and extract data from the fully rendered page. Alternatively, analyzing network requests to identify APIs that provide the data directly can be more efficient.
Optimizing ListCrawler Performance
Optimizing performance involves techniques like efficient parsing of HTML, minimizing network requests, using asynchronous operations, and implementing caching mechanisms to reduce redundant data retrieval. Careful selection of libraries and efficient code are crucial for performance.
Discover the crucial elements that make jenny popach the top choice.
Handling Pagination with ListCrawlers
Pagination is often handled by identifying patterns in URLs or HTML elements that indicate subsequent pages. ListCrawlers can then iterate through these pages, extracting data from each until all pages are processed. Regular expressions or dedicated pagination libraries can streamline this process.
Flowchart for Data Extraction with a ListCrawler
A flowchart would visually depict the steps: 1. Identify Target Website and List; 2. Analyze Website Structure; 3. Develop Extraction Logic (e.g., XPath, CSS selectors); 4. Implement Pagination Handling; 5.
Extract Data; 6. Clean and Process Data; 7. Store Data; 8. Monitor and Maintain.
Data Cleaning and Processing with ListCrawler Output

Raw data extracted by ListCrawlers often requires cleaning and processing before it can be used for analysis or other purposes. This involves handling missing data, inconsistencies, and transforming the data into a usable format.
Best Practices for Data Cleaning and Pre-processing
Best practices include removing duplicates, handling missing values (imputation or removal), standardizing data formats (e.g., date formats, currency conversions), and correcting errors or inconsistencies. Data validation techniques are crucial to ensure data quality.
Transforming Raw Data into Usable Formats
A step-by-step guide would include: 1. Data Extraction; 2. Data Cleaning; 3. Data Transformation (e.g., using Pandas in Python); 4. Data Validation; 5.
Data Storage (CSV, JSON, database). Libraries like Pandas (Python) or similar tools in other languages are commonly used for this.
Handling Missing or Inconsistent Data
Techniques include imputation (filling missing values with estimated values), removal of rows with excessive missing data, or flagging inconsistent data for manual review. The choice of method depends on the nature of the data and the impact of missing or inconsistent values on the analysis.
Data Validation Techniques
Data validation involves checking data for accuracy, completeness, and consistency. This can include checking data types, ranges, and constraints. Automated validation checks, along with manual review, are important for ensuring data quality.
Common Data Cleaning Tasks
- Removing duplicates
- Handling missing values
- Data type conversion
- Data standardization
- Error correction
- Outlier detection and handling
Ethical Considerations and Legal Implications
Using ListCrawlers responsibly requires careful consideration of ethical implications and legal restrictions. Respecting website terms of service and adhering to legal frameworks are paramount.
Ethical Implications of Using ListCrawlers
Ethical considerations include respecting website terms of service, avoiding overloading target websites, and ensuring data privacy. Misuse can lead to reputational damage and legal repercussions. Transparency and responsible data handling are key.
Legal Restrictions and Best Practices
Legal restrictions vary by jurisdiction and may involve copyright infringement, data privacy violations (GDPR, CCPA), and terms of service violations. Best practices include respecting robots.txt directives, avoiding excessive requests, and obtaining consent where required.
Importance of Respecting robots.txt and Website Terms of Service
robots.txt is a file that indicates which parts of a website should not be accessed by web crawlers. Ignoring this can lead to website blocking and legal issues. Terms of service often specify acceptable use of website data; violating these terms can result in legal action.
Scenarios Raising Ethical or Legal Concerns
Examples include scraping personal data without consent, violating copyright by copying content without permission, overloading a website with requests causing denial-of-service, or using scraped data for illegal activities.
Potential Legal Consequences of ListCrawler Misuse
| Action | Potential Legal Consequences |
|---|---|
| Violating terms of service | Cease and desist letter, lawsuits for breach of contract |
| Copyright infringement | Lawsuits for copyright infringement, injunctions |
| Data privacy violations (GDPR, CCPA) | Significant fines, legal action |
Advanced ListCrawler Techniques and Applications
Advanced techniques enhance ListCrawler capabilities, enabling efficient data acquisition even in the face of anti-scraping measures. This section explores advanced techniques and applications.
Handling CAPTCHAs and Anti-Scraping Measures
Techniques include using CAPTCHA-solving services (with ethical considerations), employing techniques to mimic human behavior (random delays, varied user agents), and developing robust error handling to deal with anti-scraping mechanisms.
Use of Proxies and Rotating IP Addresses
Proxies and rotating IP addresses help to mask the ListCrawler’s identity and prevent it from being blocked by websites. This allows for more consistent data extraction, especially when dealing with websites that actively block automated requests.
Comparison of Programming Languages for ListCrawlers
Python, with its extensive libraries (Beautiful Soup, Scrapy, Selenium), is a popular choice. Other languages like Node.js (with libraries like Cheerio) or Java are also suitable, each with its strengths and weaknesses depending on the project’s needs.
Advanced Data Analysis and Visualization
Advanced techniques involve using data analysis libraries (Pandas, NumPy in Python) for data cleaning, transformation, and statistical analysis. Data visualization tools (Matplotlib, Seaborn in Python) create insightful charts and graphs to communicate findings.
Architecture of a Robust and Scalable ListCrawler System
A conceptual illustration would show components like a web crawler module (handling requests and data extraction), a data processing module (cleaning, transformation), a data storage module (database or file system), and a user interface (for monitoring and managing the crawler). The system would incorporate error handling, logging, and scalability features.
Ultimately, ListCrawler presents a potent solution for efficient data acquisition, but its effective and ethical implementation hinges on a thorough understanding of its capabilities and limitations. By mastering the techniques Artikeld in this guide, and by consistently adhering to ethical and legal standards, users can leverage ListCrawler to unlock valuable insights from online data sources. Remember that responsible data extraction is paramount, and respecting website terms of service and robots.txt is crucial for avoiding legal repercussions and maintaining the integrity of the web.
Essential Questionnaire: Listcrowler
What programming languages are best suited for building ListCrawlers?
Python, with its extensive libraries like Beautiful Soup and Scrapy, is a popular choice. Other languages like Java, JavaScript (Node.js), and R can also be used, depending on specific needs and developer expertise.
How can I handle rate limiting when using a ListCrawler?
Implement delays between requests using time.sleep() in Python, or equivalent functions in other languages. Consider using proxies and rotating IP addresses to distribute the load across multiple IP addresses.
What are some common data cleaning tasks performed on ListCrawler extracted data?
Common tasks include removing duplicate entries, handling missing values (imputation or removal), converting data types, standardizing formats (dates, numbers), and cleaning up inconsistent data entries (e.g., correcting spelling errors).
